It runs while you sleep. That is the line that sells it — and the line that hides everything that goes wrong at 3 a.m.
If you spend any time on developer forums right now, you have seen the genre: someone runs their "solo company" as a roster of AI-agent departments. A sales agent qualifying leads, a support agent answering tickets, an ops agent reconciling data, a research agent feeding them all, quietly humming away without a payroll. It is a genuinely exciting idea, and the posts that describe it earn thousands of reactions because everyone wants it to be true. So I built a version of it across our own operations to find out where the story holds and where it falls apart.
Here is the honest report. A surprising amount of it works, and works well enough to keep. And then there is a specific, predictable place where the whole thing tears — and it is never the place the demos prepare you for. This is the teardown: what I set up, what actually held, what broke, and what I would tell anyone about to wire their business together out of agents.
The Setup, Honestly
I want to be fair to the idea, so let me describe what I actually built rather than a strawman. Each "department" was a focused agent with a narrow remit, access to specific tools, and a prompt that defined its job. The research agent gathered and summarised. A drafting agent turned briefs into first drafts. A triage agent sorted incoming requests and routed them. A data agent did routine reconciliation and flagged anomalies. On a whiteboard it looked exactly like the diagrams you have seen: tidy boxes, clean arrows between them, work flowing left to right while I watched.
The seductive part is how good the first run looks. You give the system a goal, and you watch the agents pick it up, pass it along, and produce something at the end. It feels like you have hired a small, fast, tireless team. For the length of a demo, you have. The trouble only shows up when you run it a hundred times instead of once, on real inputs instead of the clean example you tested with — which is, of course, the entire point of running a company rather than a demo.
What Actually Worked (and Is Worth Keeping)
Let me not bury the good news, because it is real and it is the reason any of this is worth doing. Single agents, pointed at single well-defined jobs, are excellent. Where a task was bounded, repetitive, and tolerant of a quick human glance at the end, the agents earned their place immediately.
Drafting was a clear win — first drafts, summaries, restructuring, turning a messy brief into something 80% there in seconds. Triage was a win: sorting and routing a flood of inbound by topic and urgency is exactly the kind of pattern-matching agents do well, and getting it 90% right with a human handling the exceptions beats doing it all by hand. Research and first-pass data work were wins for the same reason — bounded scope, fast turnaround, a human spot-check at the boundary. In every one of these cases the agent was doing one job, and a person owned the result. That combination is powerful and I kept all of it.
What Broke: The Handoffs, Every Time
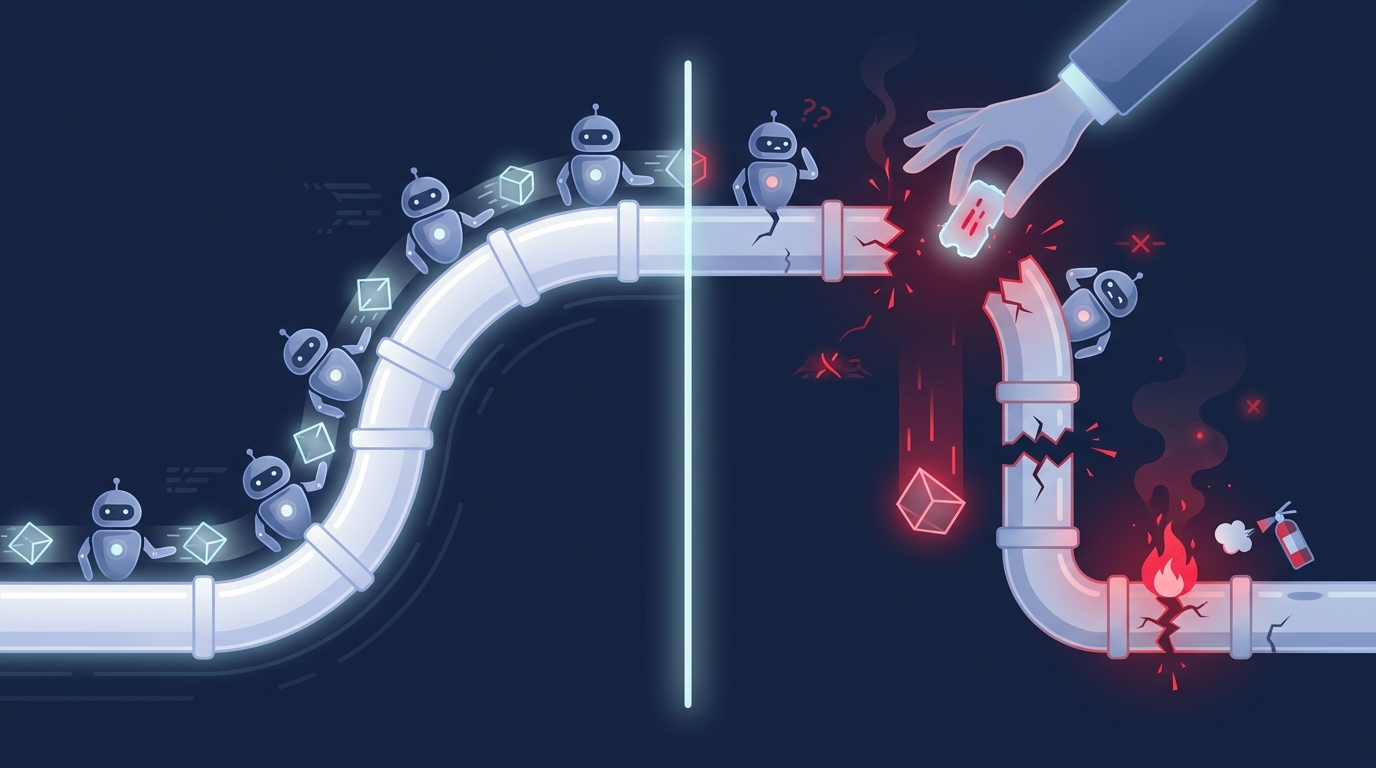
Now the part the demos skip. The moment I chained agents together — output of one becoming input of the next, unsupervised — the reliability did not just drop, it compounded downward. And it always failed in the same family of ways, at the seams rather than inside any single box.
Errors compounded down the chain. Each agent is individually pretty good — say it gets things right most of the time. String five of them together with each depending on the last, and those small error rates multiply. A slightly-off summary from the research agent becomes a subtly-wrong brief for the drafting agent becomes a confidently-wrong deliverable at the end. No single agent "failed." The chain did. By the time a problem was visible at the output, its cause was three handoffs upstream and nearly impossible to trace.
Context evaporated at the boundaries. Agents do not share a mind. What the triage agent understood about a request did not travel cleanly to the agent it handed off to; nuance, caveats, and the "why" got flattened into whatever fit in the message between them. So a downstream agent would make a locally sensible decision that was globally wrong, because it never had the context that would have told it otherwise. The handoff was lossy, and the loss accumulated.
Nobody was accountable for the whole. Each agent owned its step and nothing else. When the end result was wrong, there was no agent whose job was "make sure the overall thing is correct," because that requires holding the entire chain in view — exactly the open-ended judgement agents are weakest at. The orchestration, the part that actually runs a company, had quietly become my job, performed by frantically reading logs after something looked off.
Failure was silent. A human employee who is unsure escalates: "I'm not certain about this, can you check?" The agents almost never did. They handed their uncertain work forward with the same confidence as their easy work, so the first signal I got that something had gone wrong was a bad outcome at the end, not a flag in the middle. There was no built-in "stop and ask a human" at the risky steps unless I engineered one — and engineering all of those is most of the real work.
The Real Lesson
Here is what the teardown taught me, and it is not "AI agents don't work." It is more precise and more useful than that: the agent is the easy part; the orchestration is the hard part — and the orchestration is the company. Wiring intelligent components together into something reliable, observable, and accountable is a serious engineering problem. It is the same problem distributed systems have always had — partial failures, lost context, no single source of truth — except now each node is also non-deterministic.
This squares with what even the most bullish AI researchers say when you read them carefully. The critique of today's fully autonomous agents is not that the underlying models are weak — they are remarkable — it is that stringing them into unsupervised, multi-step autonomy is nowhere near reliable yet, and the realistic timeline for that is years of engineering, not a clever prompt. Being excited about agents long-term and sober about autonomous agent chains today are completely compatible positions. In fact they are the only honest one.
So I stopped trying to build an autonomous org chart and started building something better: narrow agents on specific jobs, a human owning the orchestration, and real engineering wherever agents had to hand work to each other. That is less magical than "it runs while I sleep." It is also the version that actually ships value instead of quietly corrupting it.
What Production-Grade Agents Actually Need
If you take the leverage seriously but respect where it breaks, you end up building a specific set of things — the unglamorous scaffolding that turns a roster of demo agents into something a business can lean on. None of it shows up in the viral post. All of it is the difference between a system and a story.
- Guardrails on every agent. Hard limits on what each agent can do and touch, so a confidently-wrong step cannot take an irreversible action. Capability, scoped on purpose.
- Defined failure behaviour. Explicit rules for what happens when an agent is uncertain or wrong — stop, flag, escalate to a human — rather than silently passing the problem downstream.
- Human checkpoints at the stakes. A person in the loop at the high-consequence steps. Not on everything — that kills the leverage — but on the decisions that are expensive to get wrong.
- Shared state and memory. A real source of truth the agents read from and write to, so context survives the handoff instead of being flattened into a message.
- Observability. The ability to see what every agent did, why, and where a result came from — so when something breaks three steps up, you can actually find it.
- Clear ownership of orchestration. Someone — and something — responsible for the correctness of the whole, not just the individual steps. This is the part that is genuinely engineering.
How to Be in the Winning Minority
Plenty of people will try to run their operations on autonomous agent chains this year, and most will get the same teardown I did — just more expensively, and in front of customers. The minority who get durable value from agents do a recognisable set of things differently, and you can copy all of them.
They deploy narrow agents on specific, bounded tasks and resist the urge to chain everything into unsupervised autonomy. They keep a human owning the orchestration and the outcome, treating agents as fast components rather than employees. They engineer the handoffs deliberately — shared state, explicit failure rules, checkpoints — because they have learned that the seams are where reliability is won or lost. They build observability in from the start, so a wrong result is traceable instead of mysterious. And when the orchestration gets genuinely hard — which it does the moment the work matters — they bring in engineering help rather than holding a brittle system together with their own attention at 3 a.m.
The honest reframe is freeing, not deflating. You do not have to choose between "AI agents are hype" and "fire everyone, the robots run it now." The truth in the middle is where the value is: agents are a powerful new kind of component, and turning components into a dependable business is an engineering job. Get that division of labour right — agents do the bounded work, real engineering owns the connective tissue, humans own the stakes — and you get most of the dream without the 3 a.m. surprise.
We Engineer the Part Between the Agents
Shanti Infosoft is a CMMI Level 5 software engineering firm. We build agentic systems that hold up in production — with the guardrails, shared state, human checkpoints, and observability that turn a roster of demo agents into something your business can actually depend on. You get a named senior team, written fixed-scope estimates, and full IP and source ownership.
Frequently Asked Questions
Can you really run a company on AI agents?
You can run real, useful parts of one — drafting, triage, research, first-pass support, routine data work — and get genuine leverage. What you cannot yet do is hand whole functions to fully autonomous agents and walk away. Agents are excellent at bounded, well-defined tasks and unreliable at open-ended judgement and at handing work cleanly to one another. The winning pattern is narrow agents on specific jobs with a human owning the orchestration, not an autonomous org chart.
What actually breaks when you chain AI agents together?
The handoffs. A single agent doing one task is reliable; the failure happens at the seams, where one agent's output becomes another's input. Small errors compound across the chain, agents lose context between steps, and there is no shared memory or accountability — so a wrong assumption early on quietly corrupts everything downstream. Most multi-agent failures are integration and orchestration failures, not failures of any individual agent.
Are autonomous AI agents production-ready in 2026?
Narrow, supervised agents are production-ready for specific tasks today and deliver real value. Fully autonomous, multi-step agents running unsupervised are not — they need guardrails, human checkpoints, error handling, and observability before they can be trusted with anything that matters. Even leading AI researchers describe today's fully autonomous agents as far from reliable; the realistic horizon for that level of autonomy is measured in years, not months.
What do production-grade AI agents need that a demo agent doesn't?
Guardrails on what each agent can do, defined behaviour for failure and uncertainty, human checkpoints at high-stakes steps, shared state and memory so context is not lost between agents, observability so you can see what every agent did and why, and clear ownership of the orchestration. A demo agent skips all of this; a production agent lives or dies by it.
Should small businesses avoid AI agents until they're more mature?
No — they should use them in the form that already works. Put narrow agents on bounded tasks where a human checks the output, and you get real efficiency today with very little risk. Just avoid wiring critical, multi-step workflows together into unsupervised autonomy, which is where reliability falls apart. Start where agents are strong, keep a human on the orchestration, and add engineering as the workflows grow in stakes.
Written by
Rishabh Jain
AI Consultant & Founder, Shanti Infosoft LLP
Shanti Infosoft is a CMMI Level 5 software engineering firm. We deliver every project with written, fixed-scope estimates, full IP and source-code ownership for the client, and a named team of senior engineers. We specialise in taking AI from prototype to production: 700+ projects delivered across web and mobile development, AI integration, and offshore engineering.
700+ Projects Delivered | CMMI Level 5 | 4.9★ on Clutch | 38,000+ hrs on Upwork